Much of my research involves the use of the auditory masked priming paradigm (Kouider and Dupoux, 2005; Schluter, 2013) to explore the processes underlying spoken word recognition. In a typical trial of an auditory masked priming experiment, participants will hear a prime followed immediately by the target (Figure 1), and their task is to perform some judgment to the target (e.g. judge whether it is a word).
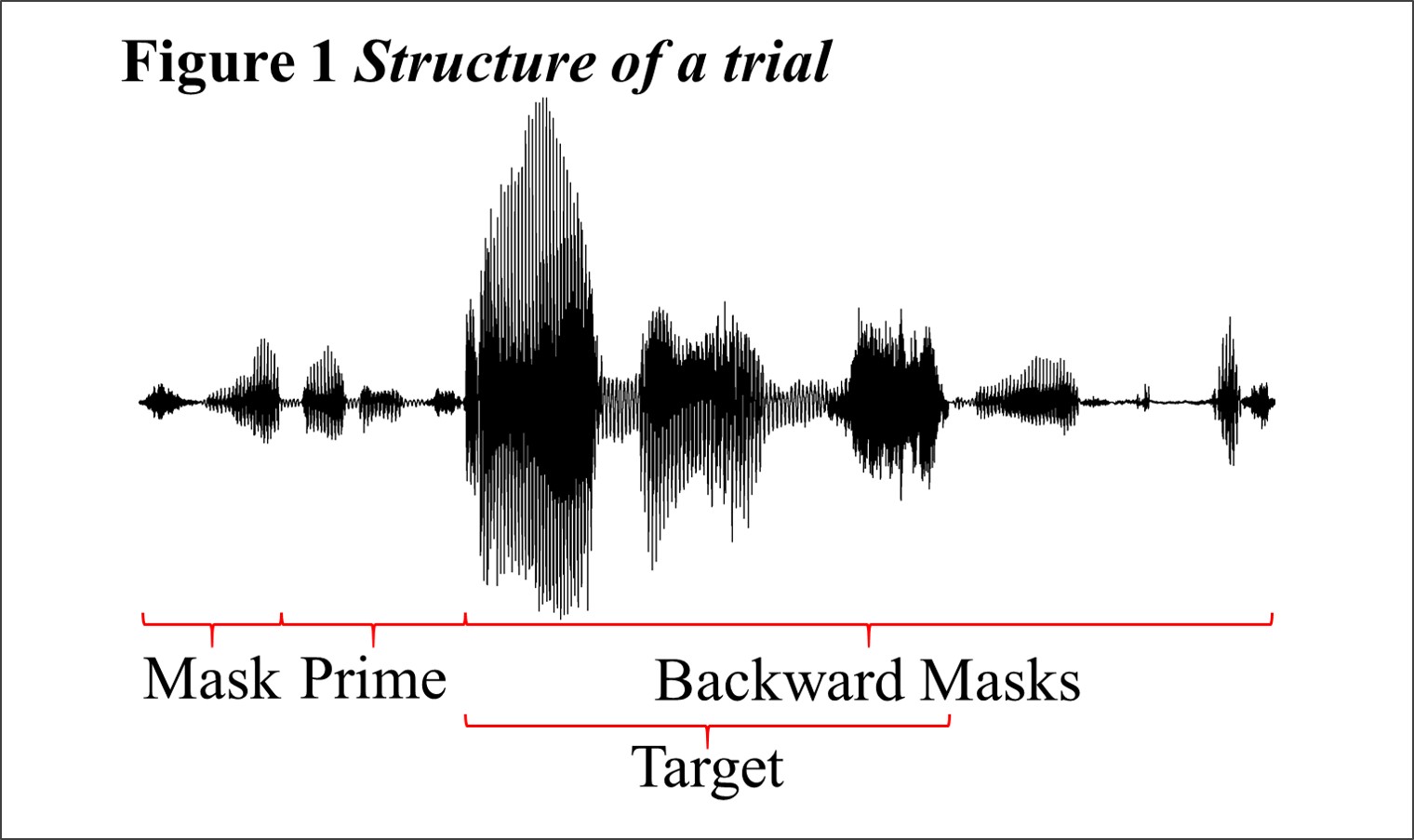
Typically, participants are not consciously aware of the existence of the prime (as in visual masked priming, some awareness of repetition primes may occur), but they process it anyway, and we know this because their response to the target changes depending on the relationship between the prime and the target. We "mask" the prime by doing three things:
- Durationally compressing the prime, either using a fixed compression rate (e.g. 35% of the target's original duration) (Kouider and Dupoux, 2005) or using a fixed compressed duration (e.g. 240 ms) (Schluter, 2013).
- Amplitude-attenuating the prime.
- Embedding the prime in a series of forward and backward masks. The masks are similarly durationally-compressed and amplitude-attenuated, but they are also played in reverse, preventing their identification.